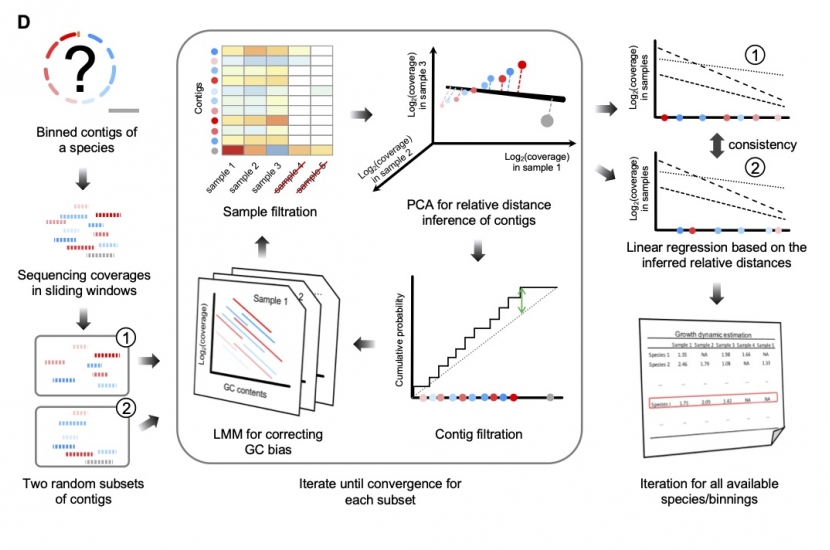
Welcome to the Center for Statistics in Biomedical Big Data (CSBBD). The CSBBD focuses on significantly advancing the state of the art in statistical inferential and computational methods for transforming large, heterogeneous, high-dimensional big data sources into predictive models for biomedicine and precision medicine.
Big data appear in all aspects of modern biomedical research. Human genetics/genomics research is increasingly characterized by high-throughput assays that can measure millions of biologic states and/or processes on any given patient sample. Human microbiome research is moving from simple associations to more mechanistic understanding of host-microbe interactions and microbiome-regulated biological processes. New mobile and wearable devices and neuroimaging technologies provide detailed predictable longitudinal phenotypes. These technologies and the resulting big data hold tremendous promise for identifying specific genomic disruptions that lead to disease and tailoring treatments based on a patient’s particular cause of disease. As a result, genomic information and deep phenotyping are expected to proliferate both in research and clinical applications. However, the data generated by these assays are extremely complex and the datasets produced are big and heterogeneous. Sophisticated computational and statistical inferential methods are required to advance our knowledge of disease biology as well as to identify important, treatment-relevant features of individual patient genomes and metagenomes. Big data in health sciences raise major statistical inferential challenges, including assessment of sampling biases, inference about tails, reproducibility of results.
The goal of the CSBBD is to develop novel statistical inference methods for big data in health sciences and to apply these methods through close collaborations with investigators at Penn.